Project Overwiew¶
OpenStreetMap(OSM) is a free, editable map of the whole world that is being built by volunteers largely from scratch and released with an open-content license.
The OpenStreetMap License allows free (or almost free) access to our map images and all of our underlying map data. The project aims to promote new and interesting uses of this data.
The data is stored in XML format and is generated by different users and therefore prone to many errors.
In this Project, I choose a map of Warsaw from the OSM and use data munging techniques to:
- Audit map data for validity, accuracy, completeness,consistency and uniformity.
- Fix the problems encountered and export the audited data from XML to CSV format .
- Store the CSV's into an sqlite database (using the selected schema) and use SQL to query and aggregate the stored data.
Map Area¶
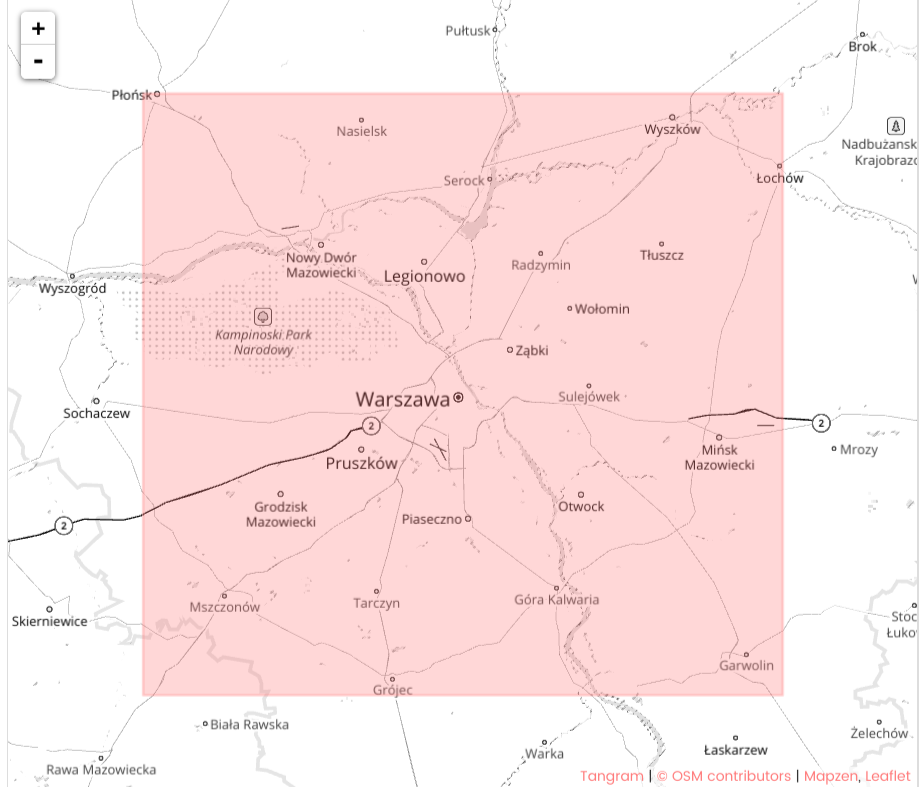
This map is from the town I probably spend most of my time over the last years. I’m quite interested to see what database querying reveals, and I’d like an opportunity to contribute to its improvement on OpenStreetMap.org.
It is the suggested Metro Extract and the overall filesize of the unzipped xml file is ~1.2 Gb.
Problems Encountered in the Map¶
After initially downloading a smaller sample size of the Warsaw I started the wrangling process by investigating the various elements.
I did not find any problems with street abreviations as it often happens, because only the name of the street is used.
In cases of square the description plac is correctly used.
The problems encountered, and I will discuss are the following:
Inconsistent or overlapping building types ('boat', 'boathouse','houseboat' or 'civ','civic')
Inconsistent phone numbers(+ 48 22 620, 00482263210, 22 31 82 80 )
Inconsistent and Inaccurate Cafe Names (Costa Coffee, Costa Coffee, Green Caffè Nero, Green Caffe Nero etc).
Inconsistent or overlapping building types¶
Looking into the key:building I noticed that there are many custom entries that do not appear at the wiky for this 'key' and have only one entry in Warsaw map
as well as in the entire OSM Database.
Auditing, for uniformity and consistency I choose to follow the logic described at the Key:building - wiki page and use the json provided by the API with the most common values to filter the values of my map based on their number of occurences or the existence of a wiki entry.
The number of building values that did not have a wiki entry and had less than 5 occurences in the OSM db where 59.
I audited the majority of them using the function correct_building() from the file audit.py, attempting to match general patterns observed in the map, in the following fashion:
def correct_building(val):
if val in building_mapping.keys():
return building_mapping[val]
else:
if 'shop' in val or 'store' in val or 'retail' in val or 'food' in val:
building_mapping[val] = 'retail'
elif 'office' in val or 'commercial' in val:
building_mapping[val] = 'commercial'
elif 'residential' in val:
building_mapping[val] = 'apartments'
elif 'muse' in val:
building_mapping[val] = 'museum'
elif 'ruin' in val or 'collapsed' in val:
building_mapping[val] = 'ruins'
...
else:
building_mapping[val]=val
return building_mapping[val]
The function uses a global dictionary that it updates for every value it is called.
The following keys:
'belfry','cage','corridor','empty','enclosing','military','no',,'part','passage','prison','tent','terminal',
'tower', 'tribunes', 'iy'
where not mapped since I could not find an adequate category for these without being in danger of deleting precious information.
After standardizing the key:building running the below SQL query we get 89 distinct entries for the building key.
The top 10 values sorted by the count we get for the building key are the following:
#DON'T RUN
SELECT tags.value, COUNT(*) as count
FROM (SELECT * FROM nodes_tags
UNION ALL
SELECT * FROM ways_tags) as tags
WHERE tags.key='building'
GROUP BY tags.value
ORDER BY count DESC
LIMIT 10;
And the 10 last ones:
#DON'T RUN
SELECT tags.value, COUNT(*) as count
FROM (SELECT * FROM nodes_tags
UNION ALL
SELECT * FROM ways_tags) as tags
WHERE tags.key='building'
GROUP BY tags.value
ORDER BY count
LIMIT 10;
Still there remains the problem of handling the values that have only one entry and ruin the consistency.
Inconsistent phone numbers¶
Looking into the phone number 'key', the entries where quite messy and Inconsistent.
According to the Key:phone - wiki the phone numbers should one of have the following two formats:
phone=+<country code> <area code> <local number>, following the ITU-T E.123 and the DIN 5008 patternphone=+<country code>-<area code>-<local number>, following the RFC 3966/NANP pattern
I chose the first one ,and again , auditing for consistence, uniformity and accuracy, used the relative functions in audit.py to transform them programatically to the desired format taking into consideration the possibility that foreign numbers may exist. Multible numbers where transformed to single numbers and extra characters and letters where deleted in the following fashion:
Mapped: +48 225827500 => +48 22 5827500
Mapped: 662 350 728 => +48 66 2350728
Mapped: +48 22 833 56 60 => +48 22 8335660
Mapped: +48 22 822 27 50 => +48 22 8222750
Mapped: 22 870 03 07;22 870 03 76;517 129 105 => +48 22 8700307
Mapped: 226213280 => +48 22 6213280
Mapped: +48226416331 => +48 22 6416331
...
Mapped: Telefon:795 975 644 => +48 79 5975644
...Inconsistent Cafe Names¶
After storing the data in database and querying for the Cafe chains I noticed there are quite a few overlapping and inconsistent values and looked like this:
#DON'T RUN
SELECT a.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags UNION ALL SELECT * FROM ways_tags) as a
JOIN
(SELECT DISTINCT(id) FROM nodes_tags WHERE nodes_tags.value='cafe'
AND nodes_tags.id NOT IN
(SELECT ways_nodes.node_id FROM ways_nodes
JOIN
(SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='cafe') as b
ON ways_nodes.id = b.id)
UNION ALL
SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='cafe') as c
ON a.id=c.id
WHERE a.key='name'
GROUP BY a.value
ORDER BY num DESC
LIMIT 10;
I used the function correct_cafe_names() to audit and correct the cafe names in a fashion similar to the correct_building() function I described above with the difference that I used a boolean switch to identify the elements that had the value cafe in their tag attributes.
Data Overview¶
This section contains basic statistics, some further exploration of the dataset and the SQL queries used to gather them and aggregate the data.
File sizes¶
After running data.py and importing the resulting CSV's into a SQLite Database the following files where created:
warsaw_poland.osm...............1.2Gb
warsaw_poland_nodes.csv.........383Mb
warsaw_poland_nodes_tags.csv.....87Mb
warsaw_poland_ways.csv...........37Mb
warsaw_poland_ways_nodes.csv....136Mb
warsaw_poland_ways_tags.csv......66Mb
warsaw_Poland.db................655Mb
I will use the ipython-sql module to connect to the database and get my results into padas.
First , connect to the Database.
%load_ext sql
%sql sqlite:///warsaw_poland.db
And set some parameters
%config SqlMagic.feedback = False
Number of Nodes¶
%sql SELECT COUNT(*) as Number_of_Nodes FROM nodes
Number of Ways¶
%sql SELECT COUNT(*) as Number_of_Ways FROM ways
Number of unique users¶
%%sql
SELECT COUNT(DISTINCT(sq.uid)) as 'Number of unique users'
FROM (SELECT uid FROM nodes UNION ALL SELECT uid FROM ways) as sq;
Top 10 contributing users¶
%%sql
SELECT sq.user, COUNT(*) as num
FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) as sq
GROUP BY sq.user
ORDER BY num DESC
LIMIT 10;
Number of total entries¶
%%sql
SELECT SUM(num) as tot_num
FROM
(SELECT COUNT(*) as num
FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) as sq
GROUP BY sq.user)
Number of users appearing only once (having 1 post)¶
SELECT COUNT(*)
FROM
(SELECT sq.user, COUNT(*) as num
FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) as sq
GROUP BY sq.user
HAVING num=1);
Top user rosomak has 28.36% of the total entries in the map and the top three users represent 39% of the total entries.
The top 10 contributing users represent 55% of the total entries.
We will import the results in Pandas and visualize them
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use('seaborn-ticks')
#capture all conributing users
result = %sql SELECT sq.user, COUNT(*) as num FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) as sq GROUP BY sq.user ORDER BY num DESC
#get them in a dataframe
df = result.DataFrame()
plt.figure(figsize=(14,6))
sns.violinplot(df['num'])
plt.title('Violin plot of user entries');

plt.figure(figsize=(16,6))
result.pie()
plt.title('Piechart of user per entries');

The above plots make it very clear how much of the map is actually created by just a few users
Top 10 appearing amenities in nodes¶
SELECT value, COUNT(*) as num
FROM nodes_tags
WHERE key='amenity'
GROUP BY value
ORDER BY num DESC
LIMIT 10;
Top 10 appearing amenities in ways¶
SELECT value, COUNT(*) as num
FROM ways_tags
WHERE key='amenity'
GROUP BY value
ORDER BY num DESC
LIMIT 10;
Top 10 popular cuisines¶
Including both ways and nodes and filtered for any values that could be duplicate by looking at ways_nodes table.
%%sql
SELECT a.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags UNION ALL SELECT * FROM ways_tags) as a
JOIN
(SELECT DISTINCT(id) FROM nodes_tags WHERE nodes_tags.value='restaurant'
AND nodes_tags.id NOT IN
(SELECT ways_nodes.node_id FROM ways_nodes
JOIN
(SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='restaurant') as b
ON ways_nodes.id = b.id)
UNION ALL
SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='restaurant') as c
ON a.id=c.id
WHERE a.key='cuisine'
GROUP BY a.value
ORDER BY num DESC
LIMIT 10;
Pizza for the win! The results look consistent from the feeling one get's by living in the region.
Top 10 Coffeeshop Chains¶
After having cleaned the values, we can plot them using Pandas again and SQLAlchemy this time
from sqlalchemy import create_engine
localhost = 'sqlite:///warsaw_poland.db'
engine = create_engine(localhost)
df = pd.read_sql("""SELECT a.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags UNION ALL SELECT * FROM ways_tags) as a
JOIN
(SELECT DISTINCT(id) FROM nodes_tags WHERE nodes_tags.value='cafe'
AND nodes_tags.id NOT IN
(SELECT ways_nodes.node_id FROM ways_nodes
JOIN
(SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='cafe') as b
ON ways_nodes.id = b.id)
UNION ALL
SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='cafe') as c
ON a.id=c.id
WHERE a.key='name'
GROUP BY a.value
ORDER BY num DESC""", engine)
len(df)
We have 403 different coffee names
# Filter only for chains
df=df.loc[df.num>2]
len(df)
Only 8 appear to have 3 or more locations
df.groupby(['value']).sum().sort_values(['num']).plot(kind='barh', legend=False, figsize=(12,6))
plt.ylabel('')
plt.xlabel('')
plt.title('Coffeshop chain - Nos')
sns.despine();

A.Blikle and Grykan are the local brands and Costa Coffee and Green Caffè Nero are indeed dominating the cafe scene.
Which is the address of the Cafe Lukullus?¶
Looking at the full Cafe results, the Name Lukullus stood out and I wanted to find out, it's adress and contact details.
SELECT key, value, a.id
FROM
(SELECT *
FROM nodes_tags
JOIN (SELECT DISTINCT(id) FROM nodes_tags WHERE value='Lukullus') as i
ON nodes_tags.id=i.id) as a
WHERE type='addr'
OR key='phone'
OR key='website'
That is not that far away!
Although, by taking a look at the site I found six additional locations that are not included in this map.
Top 10 Fast Food Chains¶
SELECT a.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags UNION ALL SELECT * FROM ways_tags) as a
JOIN
(SELECT DISTINCT(id) FROM nodes_tags WHERE nodes_tags.value='fast_food'
AND nodes_tags.id NOT IN
(SELECT ways_nodes.node_id FROM ways_nodes
JOIN
(SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='fast_food') as b
ON ways_nodes.id = b.id)
UNION ALL
SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='fast_food') as c
ON a.id=c.id
WHERE a.key='name'
GROUP BY a.value
ORDER BY num DESC
LIMIT 10;
Additional Ideas¶
Top religions (by religion value tagged at place of worship)¶
Exploring the religion value separately for ways and tags nodes gives the following results:
For nodes:
SELECT nodes_tags.value, COUNT(*) as num
FROM nodes_tags
JOIN (SELECT DISTINCT(id) FROM nodes_tags WHERE value='place_of_worship') i
ON nodes_tags.id=i.id
WHERE nodes_tags.key='religion'
GROUP BY nodes_tags.value
ORDER BY num DESC;
And for ways:
SELECT ways_tags.value, COUNT(*) as num
FROM ways_tags
JOIN (SELECT DISTINCT(id) FROM ways_tags WHERE value='place_of_worship') i
ON ways_tags.id=i.id
WHERE ways_tags.key='religion'
GROUP BY ways_tags.value
ORDER BY num DESC;
We observe that there are religions in nodes that do not appear in ways which makes sense since node elements are points in space, and way elements are regions.
The same also holds the other way around in the above aggregation for the buddhist religion which suggests that there are nodes included in the ways tags that don't correspond to the node id's.
We can find out the total unique values , including both ways and nodes and filtered for any values that could be duplicate by looking at ways_nodes table with the following query:
SELECT a.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags UNION ALL SELECT * FROM ways_tags) as a
JOIN
(SELECT DISTINCT(id) FROM nodes_tags WHERE nodes_tags.value='place_of_worship'
AND nodes_tags.id NOT IN
(SELECT ways_nodes.node_id FROM ways_nodes
JOIN
(SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='place_of_worship') as b
ON ways_nodes.id = b.id)
UNION ALL
SELECT DISTINCT(id) FROM ways_tags WHERE ways_tags.value='place_of_worship') as c
ON a.id=c.id
WHERE a.key='religion'
GROUP BY a.value
ORDER BY num DESC
LIMIT 10;
It is interesting to observe that there are no overlapping entries in node_tags and ways_tags!
This discussion implies that this may be a common phenomenon.
Subsequently, I used for this report the full SQL query above to aggregate data making sure to get all the possible values of the map.
This may suggest that way and node tags are entered independently and could include the possibility of duplicate node entries
that have been entered with different node ids.
A way to make sure that there are no duplicate node entries could be a automatic double checking, (using a nosql query possibly) at the time of a node entry at a way, of the location of the node (with some tolerance to account for small differences on map placement) and prompting the user to use the already existing one.
This could also work the other way around when a node is entered and a similar node in the vicinity already exists in a way
Further exploration of other keys, other maps as well as the map editing process can shed more light on these assumptions.
References¶
https://discussions.udacity.com/t/Inconsistent-node-and-way-values-for-key-religion-and-value-place-of-worship/250453/3
https://sqlite.org/cli.html
https://github.com/brownan/sqlite3-kernel
https://www.w3schools.com/sql/sql_join.asp
https://github.com/cs109/2015/blob/master/Lectures/Lecture4/PandasAndSQL.ipynb
https://gist.github.com/carlward/54ec1c91b62a5f911c42#file-sample_project-md